


















































































































In the rapidly evolving landscape of machine learning, the success of your algorithms is pivotal for sustained business growth. At Brickclay, a prominent machine learning services provider, we recognize the crucial role that insightful metrics play in assessing model performance. This blog explores the top 18 machine learning evaluation metrics. These metrics are significant for professionals across the spectrum, including higher management executives, chief people officers, managing directors, and country managers. Ultimately, this comprehensive guide equips you with the insights needed to evaluate machine learning algorithms effectively and pursue excellence.
Machine learning evaluation metrics
In machine learning, success hinges on measuring, analyzing, and refining algorithmic performance. Our exploration of machine learning evaluation metrics highlights the pivotal indicators that determine your models’ effectiveness. From basic measures like accuracy and precision to advanced tools like ROC-AUC, discover what empowers businesses to assess, enhance, and optimize their machine learning algorithms.
Accuracy
Accuracy is the proportion of correctly classified instances among the total instances. For example, a model achieving 95% accuracy correctly predicted 95% of instances.
Accuracy is the bedrock of any machine learning model evaluation. It represents the ratio of correctly predicted instances to the total instances. Accuracy provides a straightforward measure for higher management and country managers seeking a quick performance overview. However, accuracy alone is often insufficient for certain use cases. This includes imbalanced datasets, where false positives or negatives carry varying degrees of consequence.
![]()
Precision
Precision is the ratio of correctly predicted positive observations to the total predicted positives. Therefore, a precision of 80% means 80% of predicted positives were indeed positive.
In machine learning evaluation, precision and recall are crucial for managing directors seeking a nuanced understanding of performance. Precision measures the accuracy of positive predictions. Conversely, recall gauges the model’s ability to capture all relevant instances. Striking the right balance between precision and recall is essential, as emphasizing one might compromise the other. For instance, high precision is necessary in fraud detection to minimize false positives, while maintaining an acceptable recall level avoids missing genuine cases.
![]()
Recall (Sensitivity)
Recall is the ratio of correctly predicted positive observations to all actual positives. A strong recall captured 75% of all positive instances.
In contrast to precision, recall (or sensitivity) is vital when detecting as many positive instances as possible is paramount. This applies to applications like fraud detection. Recall measures the ratio of correctly predicted positive observations to all actual positives. It ensures your model does not overlook critical cases.
![]()
F1 score
The F1 score serves as a harmonizing metric for precision and recall. It encapsulates both measures into a single value, providing a comprehensive model performance overview. This metric is particularly valuable for Chief People Officers. It ensures that machine learning models strike an optimal balance between making accurate predictions and capturing relevant instances. Furthermore, the F1 score is especially effective when the consequences of false positives and false negatives are equally significant.
![]()
Area under the ROC curve (AUC-ROC)
AUC-ROC represents the area under the receiver operating characteristic curve. For instance, an AUC-ROC of 0.95 signifies a strong model.
For classification models, the Receiver Operating Characteristic (ROC) curve and the Area Under the Curve (AUC-ROC) are indispensable. ROC curves illustrate the trade-off between sensitivity and specificity at various thresholds. They provide a comprehensive view of a model’s performance across different decision thresholds. Conversely, AUC-ROC condenses the information from the ROC curve into a single value. This simplifies the evaluation process for higher management and country managers who need to understand a classification model’s discriminatory power.
Confusion matrix
The confusion matrix is a powerful tool. It presents a detailed breakdown of a model’s performance, offering insights into true positives, true negatives, false positives, and false negatives. These machine learning evaluation metrics are instrumental for managing directors and country managers. They gain a comprehensive understanding of a machine learning model’s strengths and weaknesses. Importantly, the matrix provides a basis for refining the model and optimizing its performance based on specific business objectives.
Regression model evaluation metrics
Mean absolute error (MAE)
MAE is a critical metric that provides a straightforward measure of prediction accuracy in regression model evaluation. It calculates the average of the absolute differences between predicted and actual values. Consequently, MAE offers a clear picture of the model’s predictive performance.
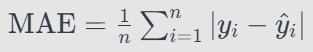
Mean squared error (MSE)
MSE is another fundamental metric for regression models, similar to MAE. It places a higher weight on larger errors by squaring the differences between predicted and actual values. Thus, it provides insights into the overall variability in your model’s predictions.
![]()
Root mean squared error (RMSE)
RMSE adds a layer of interpretability to MSE. It provides the same unit as the dependent variable. This makes it more user-friendly and easier to communicate to stakeholders who may not be deeply versed in the technical aspects of machine learning.
![]()
R-squared (R²)
R-squared is a key metric for evaluating regression models. It provides insights into the proportion of variance in the dependent variable explained by the model. For managing directors and country managers, understanding R-squared is crucial for assessing the model’s predictive power. Furthermore, a high R-squared indicates that the model captures a significant proportion of the variability in the dependent variable, making it a valuable tool for decision-making.
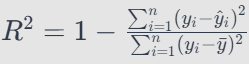
Advanced classification metrics
Mean bias deviation (MBD)
MBD helps identify systematic errors in predictions. This evaluation metric measures the average difference between predicted and actual values. Consequently, MBD offers a useful perspective on the bias present in your model and guides improvements in accuracy.
![]()
Cohen’s kappa
Cohen’s Kappa is particularly relevant when dealing with imbalanced datasets. It assesses the agreement between predicted and actual classifications, accounting for chance. Therefore, this metric provides a more nuanced evaluation, especially when class distribution is uneven.
![]()
Matthews correlation coefficient (MCC)
MCC offers a balanced assessment of binary classifications. It considers true positives, true negatives, false positives, and false negatives. It provides a comprehensive view of your model’s predictive performance, especially in scenarios where false positives and false negative consequences differ significantly.
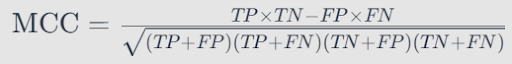
Kullback-Leibler divergence (KL Divergence)
In scenarios involving probabilistic models, KL Divergence is a valuable metric. It measures how one probability distribution diverges from a second, expected probability distribution. As a result, it provides insights into the model’s performance in capturing underlying data distributions.
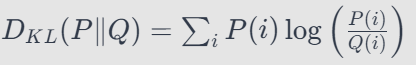
Model interpretation and robustness
Feature importance
Understanding each feature’s contribution to the model’s predictions is crucial for refining and optimizing your algorithm. Feature importance metrics help identify which features drive the model’s decisions. Consequently, this guides feature engineering efforts and enhances your model’s interpretability.
Computational efficiency
Real-world applications demand accurate predictions and efficient resource use. Computational efficiency metrics evaluate the time and resources required for model training and predictions. This ensures your solution is powerful and practical for deployment.
Cross-validation scores
Cross-validation is an essential technique for evaluating machine learning models. It ensures the model’s generalizability to new, unseen data. This involves dividing the dataset into subsets, training the model on combinations, and validating it on the remaining data. This process helps identify overfitting issues and objectively estimates a model’s performance. For Chief People Officers concerned with model robustness, cross-validation ensures the algorithm performs well in diverse scenarios.
Model robustness
A model’s ability to perform consistently across different datasets is a testament to its robustness. These machine learning metrics ensure your model is not overly specialized. Thus, it can generalize well to new, unseen data. In the ever-evolving metrics landscape for machine learning, model robustness is critical for sustained success and adaptability.
In the competitive landscape of machine learning services, the ability to assess and refine algorithms is a strategic imperative. By leveraging these metrics, Brickclay continues to uphold its commitment to delivering cutting-edge machine-learning solutions that drive success in an ever-evolving business landscape. Evaluating machine learning algorithms remains an ongoing and dynamic process as the technological frontier advances. Therefore, staying abreast of these metrics is your key to unlocking sustained success.
Why machine learning evaluation metrics matter
We cannot overstate the importance of machine learning evaluation metrics in developing and deploying models. These metrics serve as quantitative measures to assess machine learning algorithms’ performance, reliability, and effectiveness. Here are key reasons highlighting the importance of these metrics:
- Quantifying Model Performance: Evaluation metrics provide a standardized, quantitative way to measure how well a machine learning model performs.
- Informing Model Selection: Different machine learning models may perform differently on the same dataset. Consequently, evaluation metrics assist in selecting the most suitable model for a specific task.
- Handling Imbalanced Datasets: Datasets are often imbalanced in real-world scenarios, where one class significantly outnumbers the other. Evaluation metrics help handle and mitigate the impact of class imbalances.
- Optimizing Model Parameters: Evaluation metrics guide the fine-tuning of model parameters to achieve optimal performance.
- Understanding Model Behavior: Evaluation metrics, especially confusion matrices, provide detailed insights into a model’s behavior, highlighting areas of strength and weakness.
- Handling Business Objectives: Metrics can be tailored to align with specific business objectives, ensuring the model’s performance aligns with organizational goals.
- Interpretable and Explainable Results: Clear, interpretable metrics make it easier for stakeholders, including non-technical decision-makers, to understand and trust the model’s output.
- Identifying Overfitting and Underfitting: Machine learning evaluation metrics help diagnose common issues like overfitting or underfitting, ensuring the model generalizes well to new, unseen data.
- Continuous Model Improvement: Regularly evaluating models allows for continuous improvement. This ensures machine learning solutions remain effective over time as data distributions and requirements evolve.
- Ensuring Ethical AI: Evaluation metrics ensure machine learning models are fair, unbiased, and do not inadvertently discriminate against certain groups.
How can Brickclay help?
At Brickclay, we understand that any business’s success lies in harnessing the transformative potential of cutting-edge technologies. We meticulously craft our machine learning services to empower businesses across industries. We provide unparalleled insights and foster strategic decision-making. Here is how Brickclay acts as your catalyst for success:
Driving performance and precision
- Precision and Performance Optimization: Brickclay’s machine learning algorithms deliver precision and accuracy in predictions. We optimize performance by fine-tuning models through advanced evaluation metrics. This ensures your business makes informed decisions based on reliable data.
- Tailored Solutions for Every Business Need: We recognize that each business is unique, with its own challenges and objectives. Therefore, we tailor our machine learning services to meet your industry’s specific needs. We provide customized solutions that resonate with your business goals and drive sustainable growth.
Strategic support for leadership
- Strategic Decision Support for Managing Directors: Brickclay’s machine learning services offer a comprehensive suite of metrics and tools for managing directors seeking strategic decision support. Our solutions empower leaders to make data-driven decisions that propel their organizations forward. This includes evaluating regression models and understanding the nuances of classification algorithms.
- Robustness and Generalizability for Country Managers: Country Managers overseeing diverse markets require robust and adaptable solutions. Brickclay’s machine learning services incorporate cross-validation techniques, ensuring model generalizability across different scenarios. Trust us to provide solutions that stand the test of global business dynamics.
Focusing on people and innovation
- Employee-Centric Solutions for Chief People Officers: Chief People Officers play a crucial role in organizational success. Our machine learning services extend a helping hand in this area. By leveraging predictive analytics, we assist in talent acquisition, retention, and development. This ensures your workforce remains a strategic asset in the ever-evolving business landscape.
- Continuous Innovation and Collaboration: At Brickclay, we value continuous innovation. Our machine learning evaluation metrics experts work collaboratively with your team. We stay at the forefront of technological advancements. By embracing a culture of innovation, we ensure your business stays ahead in the competitive landscape.
Ready to harness the power of machine learning and propel your business into a realm of data-driven success? Contact Brickclay today. Let our experts guide you on the path to innovation, precision, and unparalleled growth. Elevate your business with cutting-edge technology – contact us for a consultation and transform your data into a strategic asset.
general queries
Frequently asked questions
About Brickclay
Brickclay is a digital solutions provider that empowers businesses with data-driven strategies and innovative solutions. Our team of experts specializes in digital marketing, web design and development, big data and BI. We work with businesses of all sizes and industries to deliver customized, comprehensive solutions that help them achieve their goals.
More blog posts from brickclay



